
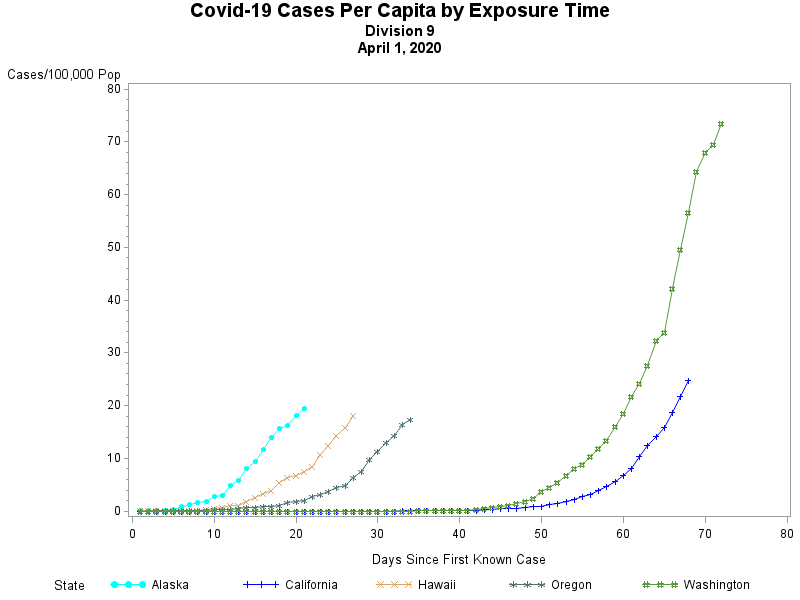
Almost anybody who is at all aware of the trends in Covid-19 vaccination progress knows these data, but it is nonetheless disheartening.
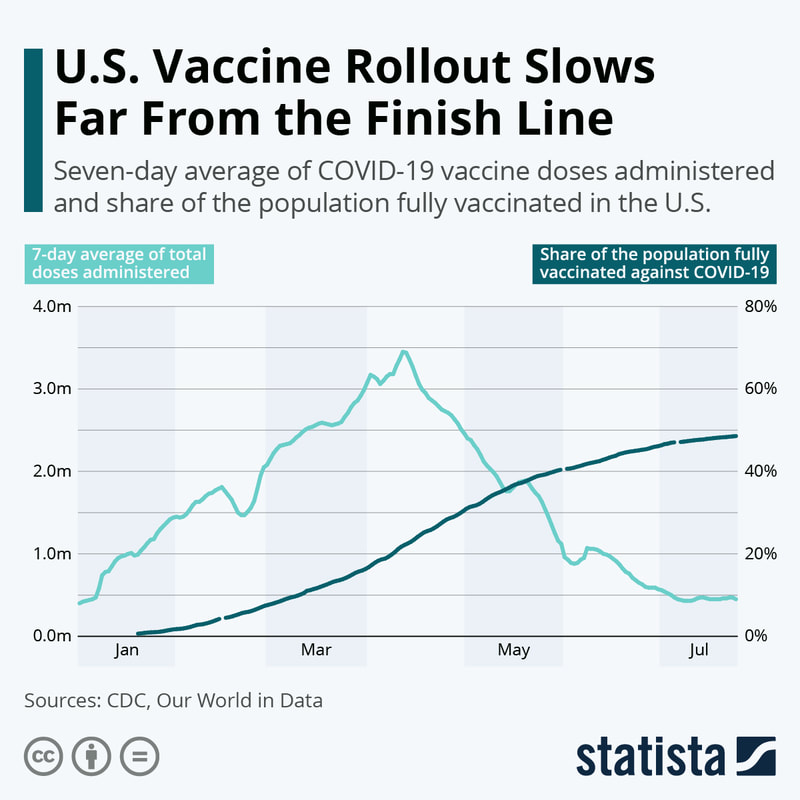
Shots per day have plummeted while the percentage of the population that is fully vaccinated has leveled off. So close -- yet so far.
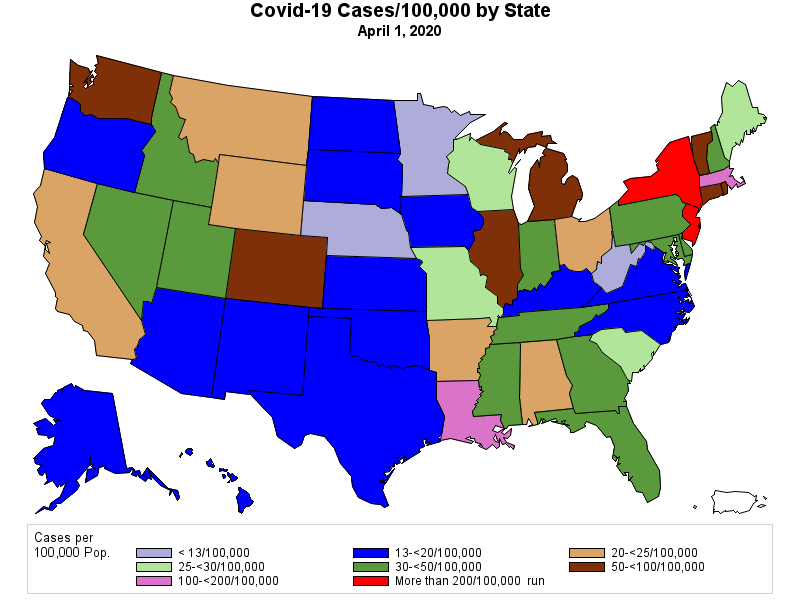
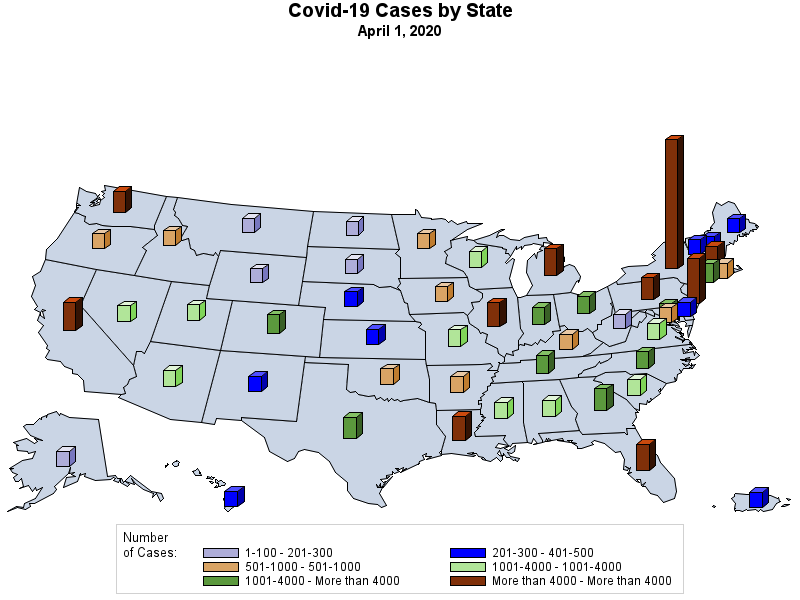
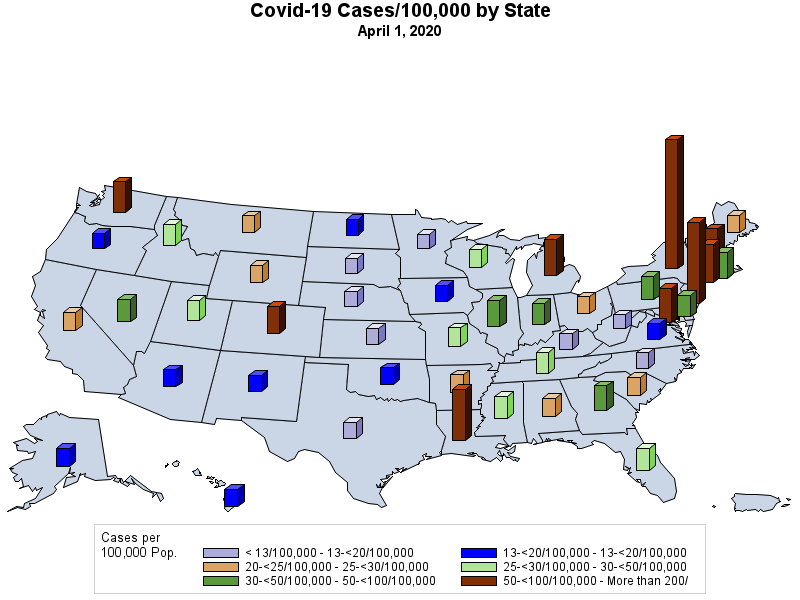
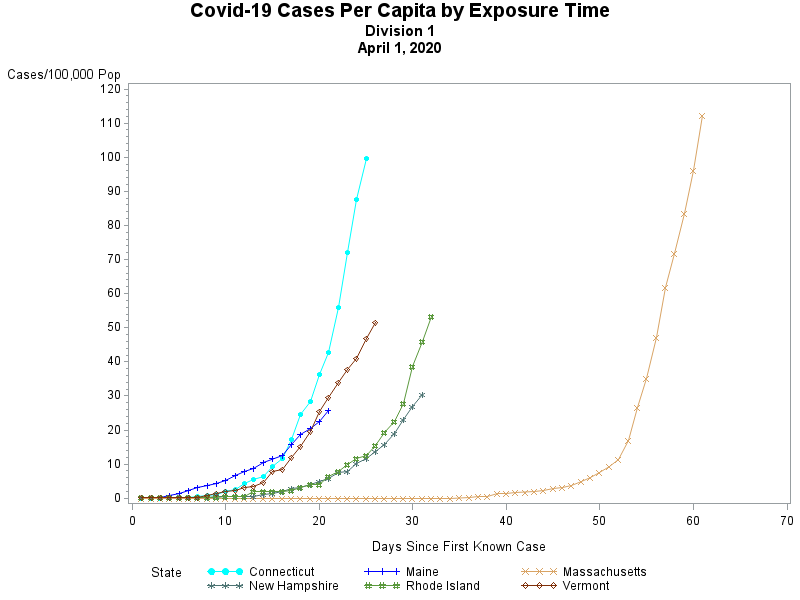
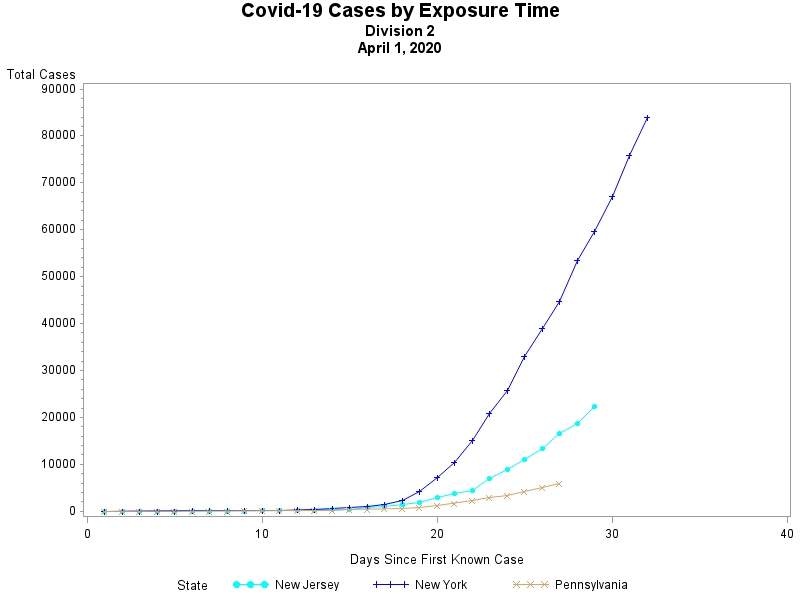
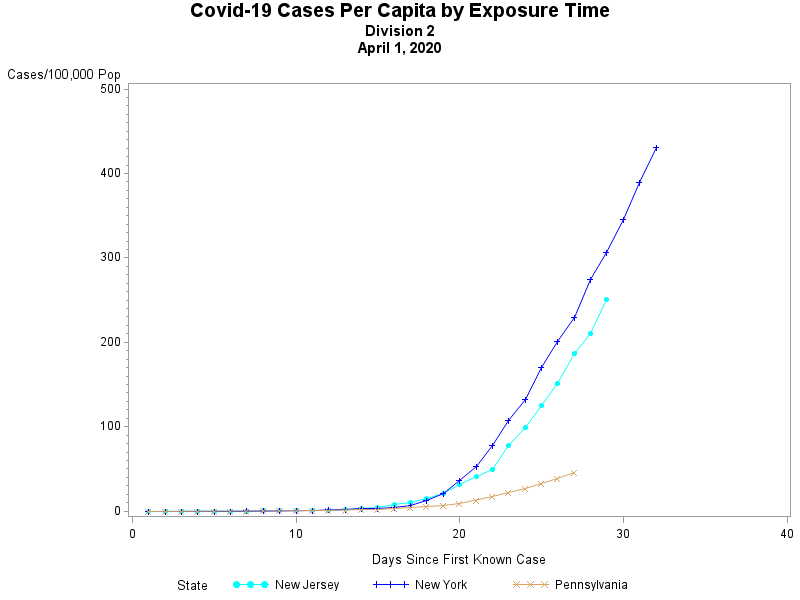
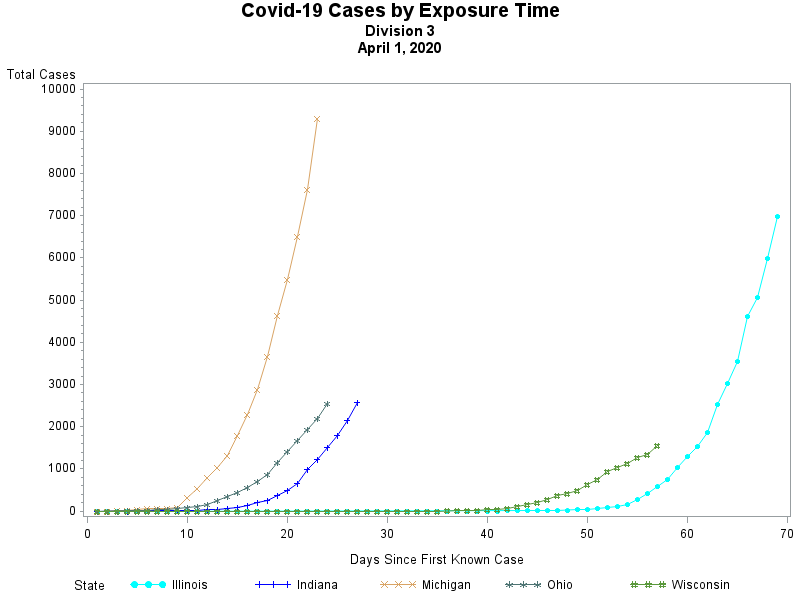
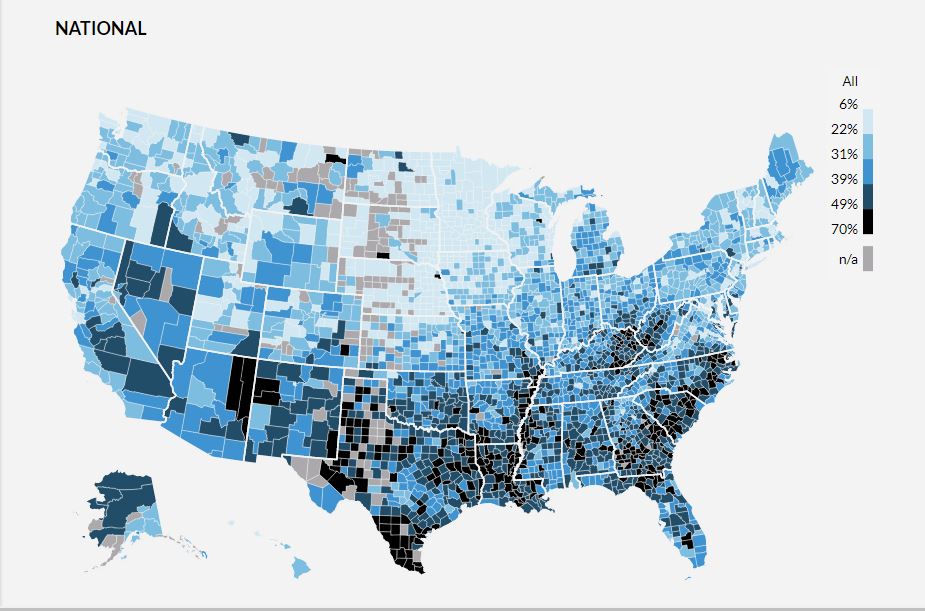
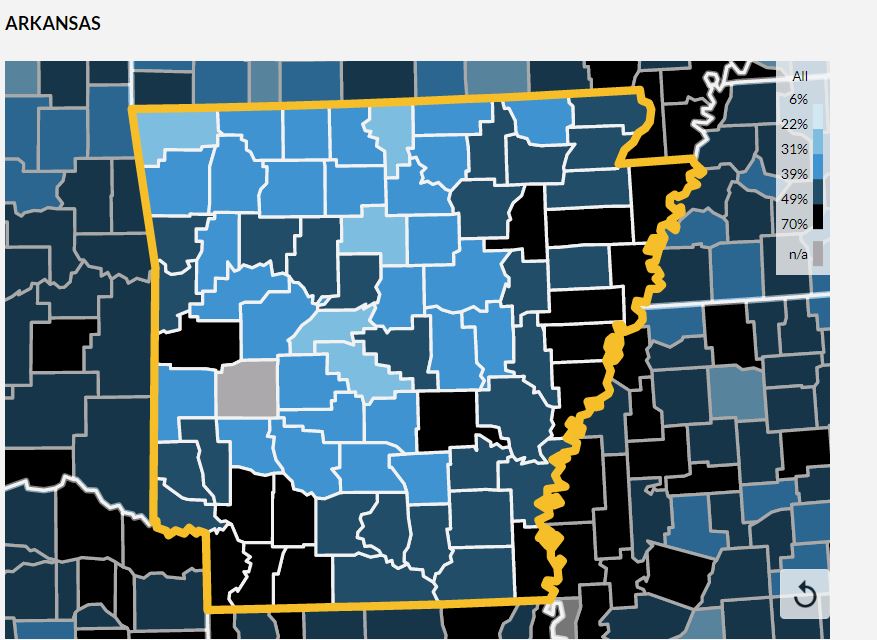
I have never been a big fan of trying to create a "map" of the United States using circles -- simply because the positioning of the states only approximates the true geography -- but the following map points out how abysmal the vaccination effort has been in many states..
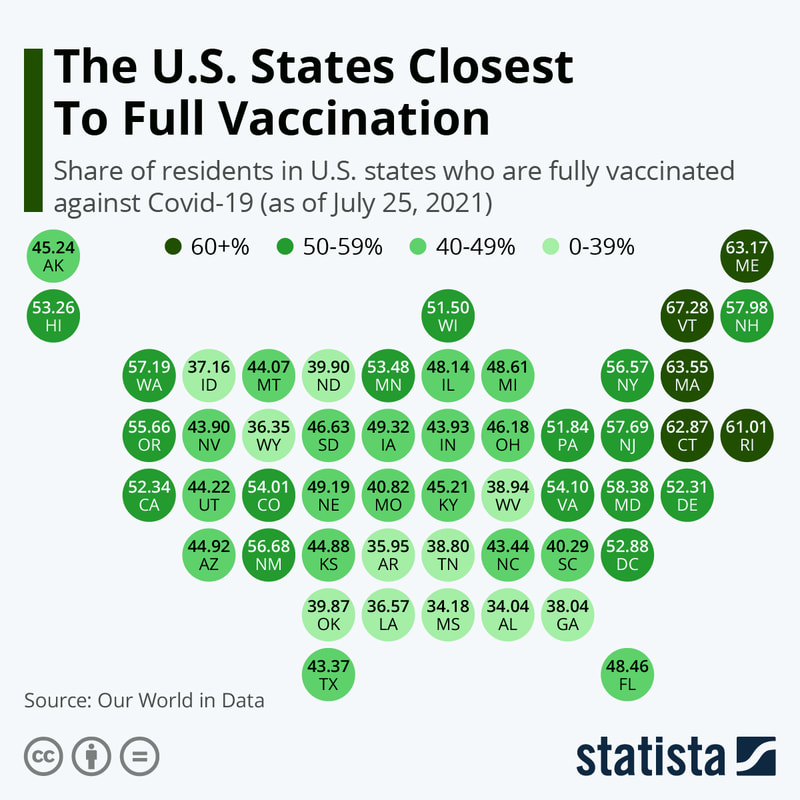
Thanks to the folks at Statista for sharing their data.
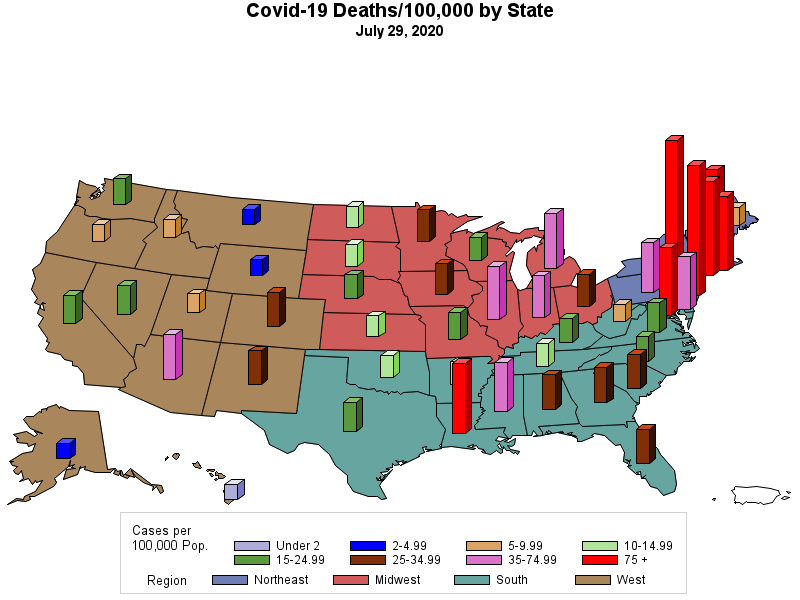
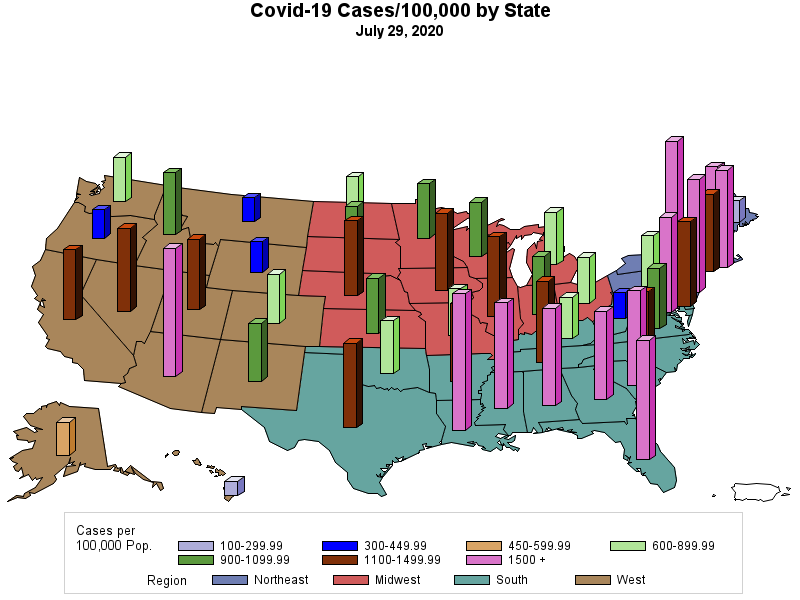
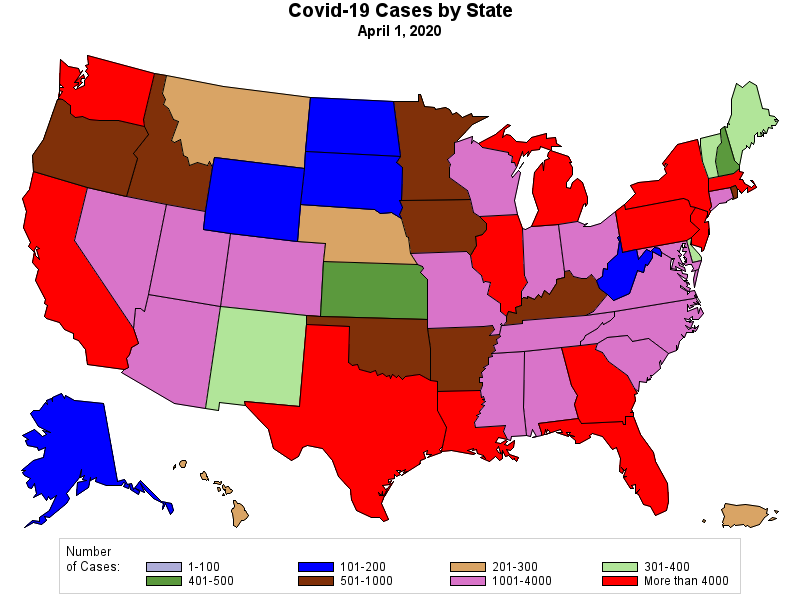
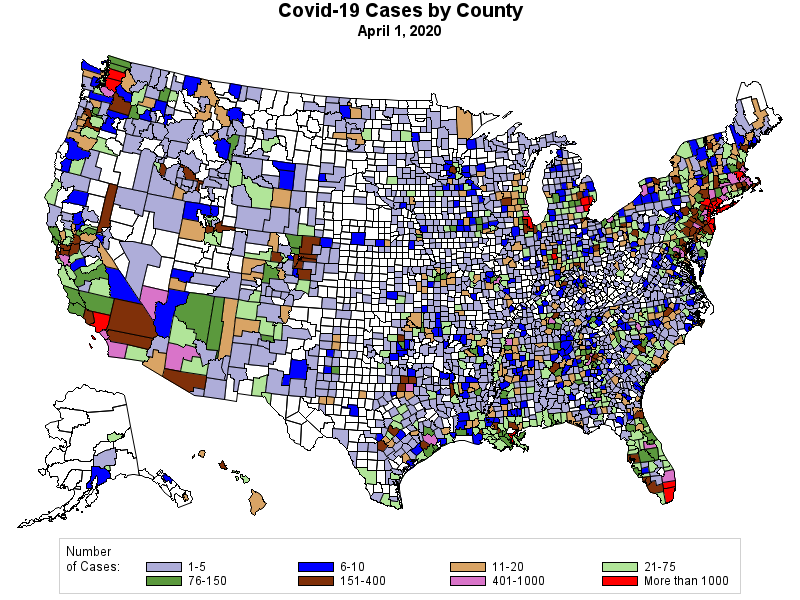
 RSS Feed
RSS Feed